𝙩𝙮≃𝙛{𝕩}^A𝕀²·ℙarad𝕚g𝕞2025-05-30 09:22:10再谈生成式AI中的“生成行为” 语言模型生成的不是“它自己需要的东西”,而是“你希望它说的东西”。 它没有一个自我持续结构;它不会为“保留某个概念”而主动调制生成路径;它也没有一个演化性机制去选择长期适应。它只是在短时上下文中模拟动机,而非真正拥有动机。 这就是所谓的“价值饥渴症”:它不断生成,却不知道为什么。 现阶段我们与LLM交互中感受到的智能,大部分是我们面对一个能说话的实体的心理投#生成式AI#语言模型#智能
𝙩𝙮≃𝙛{𝕩}^A𝕀²·ℙarad𝕚g𝕞2025-05-29 11:45:51从身之智能到心之智能是生物体的智能演化路径,现在的LLM则是直接从语言区的计算模拟生成认知智能。 在没有AI之前,我们是通过社会化网络复杂性形成共生智能,现在LLM作为exotic mind entities异类智能,会是怎样的共生symbiotic智能图景? #智能演化#语言模型#共生智能
AI Will2025-05-26 14:00:08你怎么看待这个针对语言模型的智商测试? > claude 4 opus目前以120分的离线成绩和117分的Mensa挪威测试成绩领先 > o3模型在Mensa测试中得分更高,达到了135分 这些结果令人印象深刻。 不能确定这个测试有多准确,或者它是如何衡量AI的智商的? 这或许并不是评判AI智能的最佳方式 来自:Haider. #语言模型#AI智商测试#Mensa测试
howie.serious2025-03-30 10:05:30claude团队揭秘:ai大脑不用英文也不用中文思考,而是靠“思维语言”。|这证明了英语学习/教育失败的根本原因? llm用什么语言“思考”?中文?英文? 都不是。 llms的思考,使用的不是中文或英文这样的自然语言,而是一种超越自然语言的“思维语言”。anthropic的最新研究,用实验方式首次证明了这一点,这是理解llm内部黑箱的一个巨大突破。 在llm内部,不同语言共享同一个概念空间#AI大脑#思维语言#英语学习
勃勃OC2025-02-21 09:21:06这是在反串吗? Perplexity 为 R1 抹去言论审核,补充一些全球公认的事实信息,叫“在开源社区拉屎,对中国有敌意”? 中国大语言模型的训练数据集处理流程有几十万个关键词、人工黑名单、工信部备案30年 您是知道的吧 换言之,为什么要专门去除对中国不利的消息呢? 😳😳😳 #信息审查#中国#人工审核
宝玉2025-02-03 01:17:35罗福莉(福莉),出生于四川农村的“95后AI天才少女”,现任DeepSeek公司深度学习研究员,是国产大模型DeepSeek-V2的核心开发者之一。她本科毕业于北京师范大学计算机专业,硕士保送至北京大学计算语言学专业,师从万小军教授,期间在国际顶级会议ACL上发表8篇论文(含2篇一作),奠定了其在自然语言处理(NLP)领域的学术声誉。职业生涯始于阿里巴巴达摩院,主导开发了多语言预训练模型VECO,#爱上川妹子#国产人工智能#深度学习
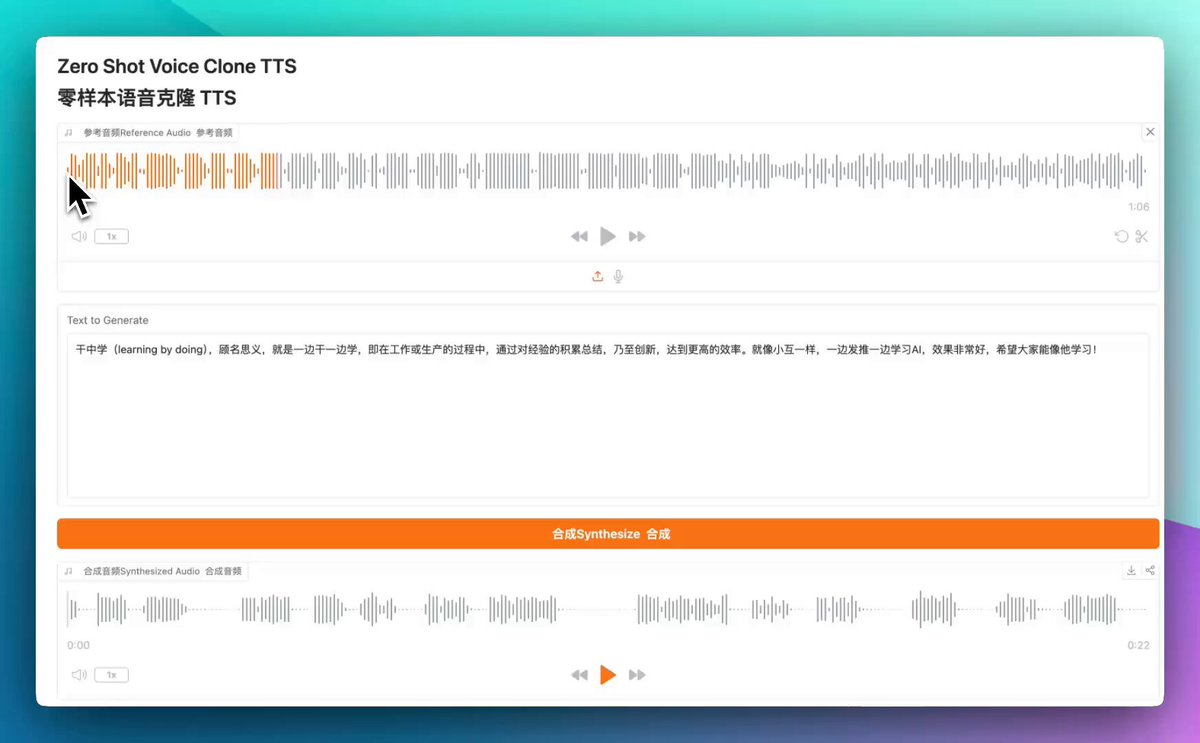
小互2025-01-25 17:01:58我去 这个语音克隆模型有点牛P 哈哈哈 使用了 250,000 小时的中英双语语音数据训练 只需15秒的声音就能完美克隆声音,保持音色和情感 Llasa-3B 可以通过输入一个带有情感特征的语音提示(Prompt),在生成目标语音时保留提示语音中的情感特征。 基于 LLaMA 语言模型( 1B、3B 和 8B 参数规模),通过整合 XCodec2 的语音 token 提供语音生成功能。#语音克隆#Llasa-3B#情感特征