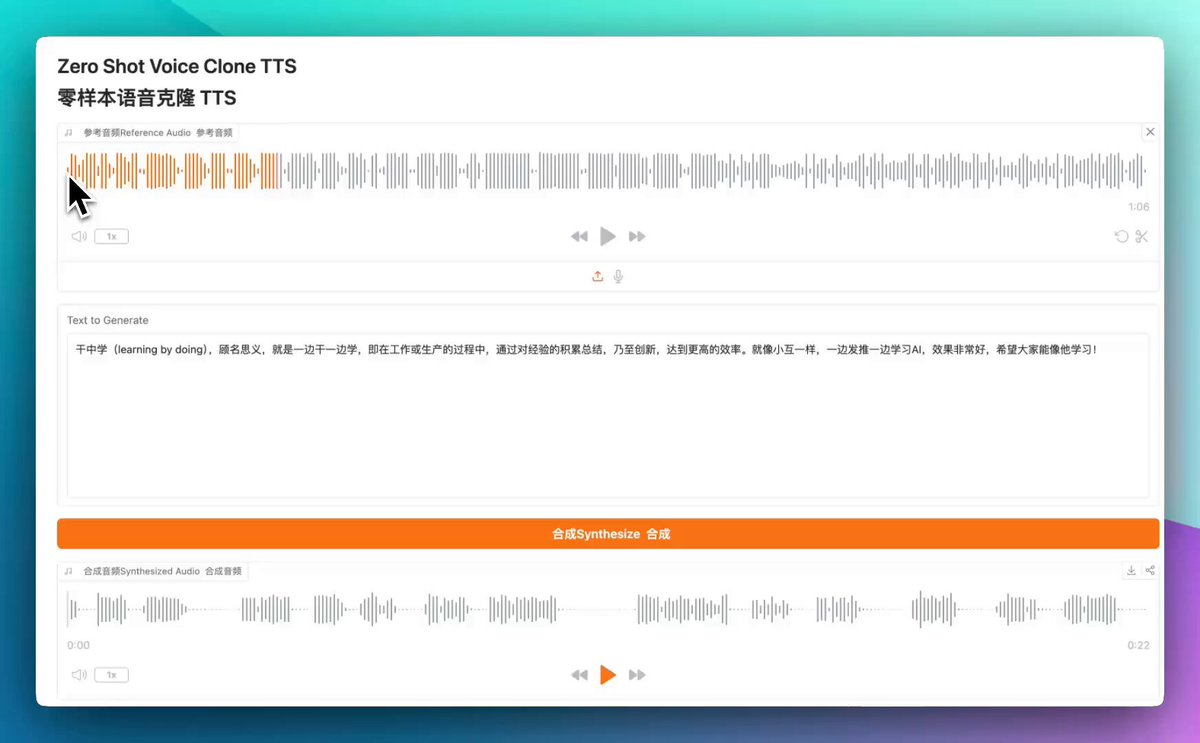
小互2025-01-25 17:01:58我去 这个语音克隆模型有点牛P 哈哈哈 使用了 250,000 小时的中英双语语音数据训练 只需15秒的声音就能完美克隆声音,保持音色和情感 Llasa-3B 可以通过输入一个带有情感特征的语音提示(Prompt),在生成目标语音时保留提示语音中的情感特征。 基于 LLaMA 语言模型( 1B、3B 和 8B 参数规模),通过整合 XCodec2 的语音 token 提供语音生成功能。#语音克隆#Llasa-3B#情感特征