Y112025-05-29 11:31:06分享5个大模型应用面试真题,各位自诩‘资深’的大模型专家,遇到如下面试题时,你会回答吗? 1. 请详细阐述你所熟悉的一种主流深度学习框架的核心特点和优势,以及你在实际项目中是如何运用它? 2. 大模型训练中遇到训练时间长,消耗大的问题,你是如何解决的请分享具体的经验。 3. RAG和Graph-based RAG各有特点,请对比这两种场景,并说明你在实际项目中是如何选择和应用它们? 4. #大模型#面试#深度学习
johann.GPT2025-05-27 17:29:14Cursor 是如何用 Merkle 树 + RAG 实现快速索引代码库? 💡 核心思路: 1️⃣ 本地用 AST 分割代码 → 构建 Merkle 树"指纹" 2️⃣ 只同步变更文件(增量更新,节省 90%+ 带宽) 3️⃣ 代码块 → Embedding 向量 → Turbopuffer 向量数据库 4️⃣ 用户提问 → 语义搜索 → 本地读取源码 → LLM 生成答案 🛡️ 隐私保护:#Merkle树#代码索引#RAG
ginobefun2025-05-26 07:25:20#BestBlogs 一文带你 "看见" MCP 的过程,彻底理解 MCP 的概念 | 阿里云开发者 深度解析 AI 上下文协议(MCP),对比 RAG 与 Function Calling,并通过实践演示理解其工作流程。 摘要: 文章详细介绍了模型上下文协议(MCP),一个旨在标准化 AI 助手与外部系统连接的开放标准。作者首先回顾了 RAG 和 Functi#AI#MCP#RAG
ginobefun2025-05-25 12:18:34#BestBlogs 淘宝 Java 工程师的 LLM 开发实践 | 大淘宝技术 从 Java 工程师视角出发,详细介绍如何使用 Spring AI 框架进行 LLM 应用开发,包括对话、Function Calling 和 RAG 实践。 摘要: 本文为 Java 工程师提供了 LLM 应用开发的实战指南。首先分析了当前 LLM 的局限性,强调了应用开发的重要#JAVA#LLM#RAG
宝玉2025-05-04 02:46:55一个专业人士,可以根据不同的问题源源不断的产生答案,随着专业能力精进还能产生更好的答案。AI只能训练这个人公开回答过的问题和答案,对于没有回答过的就不一定能回复好。当然AI的优势是基础知识库足够强大,回复速度快。另外这里说的知识库“训练”通常是指的RAG,本质上就是检索筛选,根据检索出的“片段”拼凑出答案。#专业能力#AI#知识库
idoubi2025-04-30 09:56:43关于 MCP 的几个理解误区: 1. 误区 1:MCP 协议需要大模型支持 MCP 全称模型上下文协议,是为了在用户与大模型对话过程中,补充上下文信息给大模型,让大模型更准确的回答用户提问而设计的。 在 MCP 出来之前,有多种方式可以实现上下文信息的补充,比如: - 记忆存储。把对话过程的历史消息存储下来,每次新提问,带上历史消息一起发送给大模型 - RAG。在让大模型回答问题之前,先从#MCP协议#误区#大模型
马东锡 NLP 🇸🇪2025-04-22 04:30:13「Agent, RAG, Reasoning」论文 ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning ReSearch,充满了 ReAct 的影子。它教会模型“何时求助于世界”;但局限在于,ReSearch 只能依赖一种工具。 作者提出了一种创新的框架,名为 ReSearch,旨在#agent#RAG#reasoning
Jixian Wang2025-04-21 06:35:11数据污染确实是一个不回避的问题,不过更高级的应用还是要靠Re/Act 和 RAG + MCP 的模式。 只是用模型的推理和总结能力,限制模型幻觉。 #数据污染#Re/Act#RAG
宝玉2025-04-20 15:08:54问:宝玉老师,我想请教个rag的问题。我们想通过收集时事新闻报道编写分析报告,如果采用RAG方案对新闻进行处理,数据量提供多大出来的报告比较合适,亦或者这个需求有什么别的更好的处理方案吗 答: 通常在考虑使用 AI 解决问题时,我的第一个建议是先不要考虑 RAG 这些因素,而是回归聚焦到问题本身,搞清楚要解决什么问题,然后再看要不要使用 AI 的方案,以及怎么使用 AI 的方案。 就拿这个问题#RAG#时事新闻#分析报告
宝玉2025-03-31 02:37:28问:什么是 RAG? RAG(检索增强生成,Retrieval-Augmented Generation)是一种结合了信息检索和生成式人工智能的技术。通俗地讲,它先通过检索,从数据库或互联网等外部知识源中找到与问题相关的内容,再利用生成模型(如GPT)基于这些内容生成答案。这种方式让模型不仅依靠训练时学习到的知识,还能实时获取最新信息,从而更准确地回答问题。 举个简单的例子:假设你问AI:“20#RAG#检索增强生成#信息检索
Leo Xiang2025-03-12 13:02:02OpenAI 这套开发工具把Agent开发需要的基础能力都提供了,搜索、RAG、意图识别、内容审核、Computer use 以及 Browser use,整个Agent开发的成本瞬间降低了很多。 预期可见的会出来一批Agent方向的产品。 #OpenAI#开发工具#agent
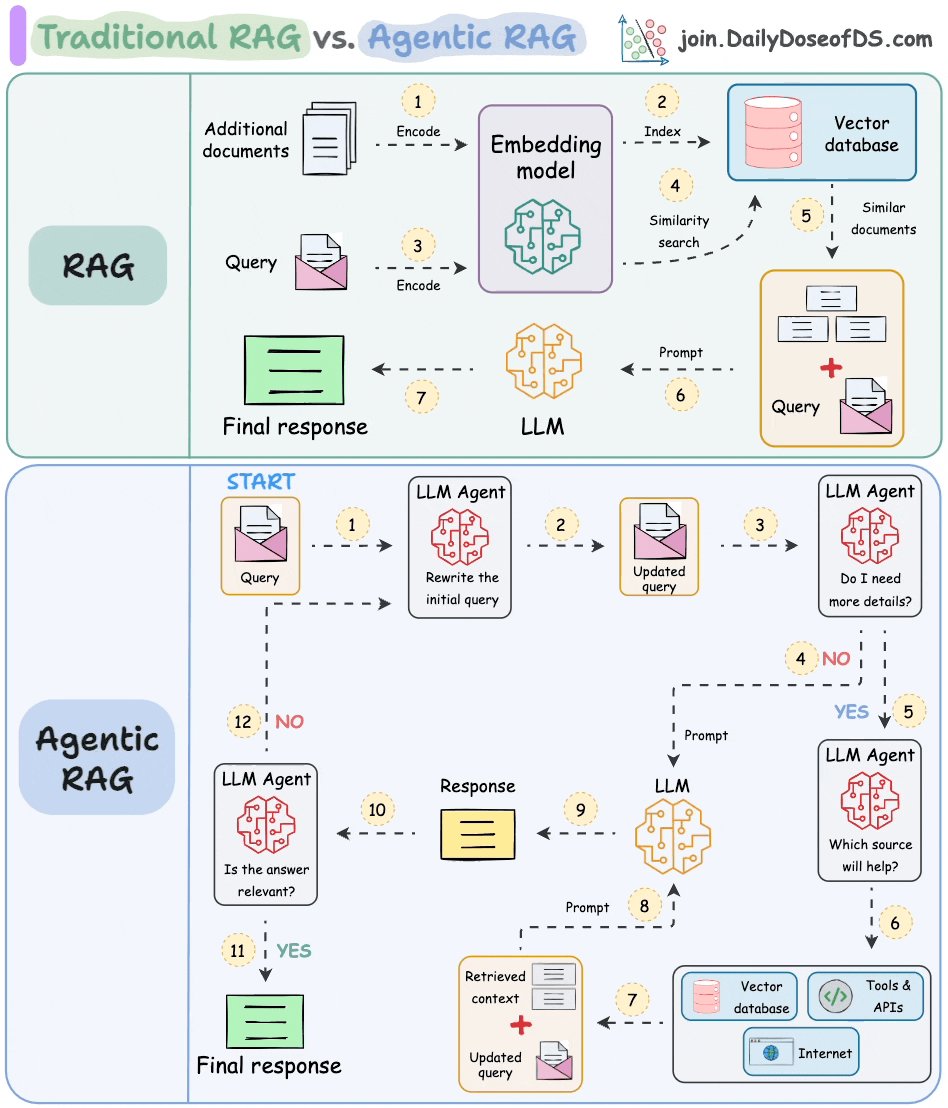
宝玉2025-01-19 04:06:36 DailyDoseofDS 这个图把传统 RAG 和 Agentic RAG 之间的差异分的比较清楚。 传统 RAG 就是先把文档向量化保存到向量数据库,然后在用户查询时,对用户的问题也做向量化,从向量数据库中找到相关的文档,再把问题和找出来的结果交给 LLM 去总结生成。 这种方式的优点就是简单,由于不需要太多次和 LLM 之间的交互,成本也相对低,但缺点是经常会因为做相似检索时,找不到合#RAG#向量数据库#LLM
biantaishabi2025-01-08 14:34:22给我的机器人加了几个工具: 编辑文件,他需要编辑部分而不是每次都是全部更新整个文件; 增加经验,(这个还需要一个搜索的,所以以后应该会把他每天批量移到一个向量数据库理让机器人搜索,以后动态构建系统提示词); 查文档的,这个项目比较简单让他读文件,还做了一个查rag的 我的机器人laoded了 #机器人#编辑文件#经验积累