張小珺 Xiaojùn2025-02-25 22:54:56长篇技术科普第三篇,关于注意力机制。 上周DeepSeek和Kimi发布了最新研究工作,我们对DeepSeek NSA、Kimi MoBA、MiniMax-01,最近的3篇注意力机制论文逐篇精读。(嘉宾松琳在MIT做注意力机制研究方向)——希望和你一起领略科技平权,感受技术之美,也希望我们能与AI共同进步🤩 #技术科普#注意力机制#AI
阑夕2025-01-24 19:06:53一年前,也是在春节期间,OpenAI突然发布了断档领先的视频大模型Sora,给国产AI厂商添了大堵,被调侃为都过不好年了。 一年后的这次临近春节,轮到中国AI厂商给美国竞对们上眼药了,Qwen、DeepSeek、Kimi、Doubao连着发大招,你方唱罢我登场,实在热闹。 因为别人太强而过不好年,和因为自个忙起来根本就没想过好年,是完全不同的两码事。 字节跳动新发布的豆包1.5 Pro,除了#OpenAI#视频大模型Sora#国产AI厂商
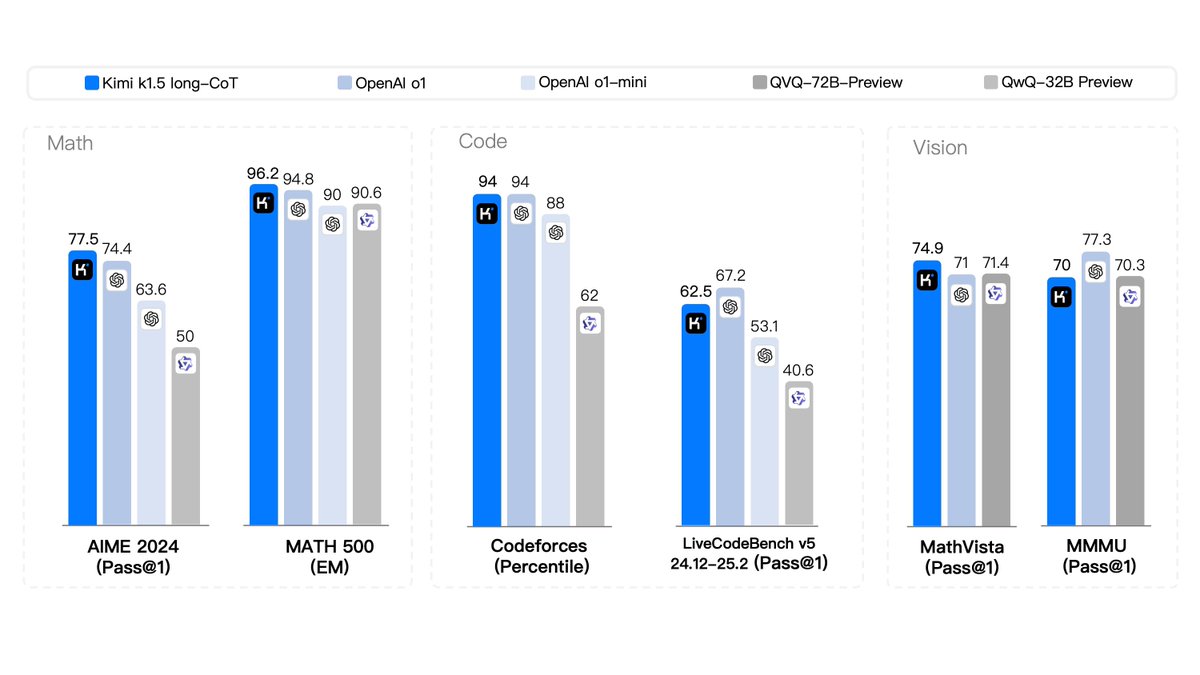
向阳乔木2025-01-22 23:45:13最近牛逼的模型都用到了这个论文提到的类似技术,从kimi k1.5到deepseek r1,到谷歌最新的flash thinking 实验版 01-21。 看来这篇论文要成为AI必读了,Mark下,明天就学。#AI技术#Kimi#DeepSeek
阑夕2025-01-22 21:22:29Kimi和DeepSeek的新模型这几天内同时发布,又是一波让人看不懂的突飞猛进,硅谷的反应也很有意思, 已经不再是惊讶「他们是怎么办到的」,而是变成了「他们是怎么能这么快的」,就快走完了质疑、理解、成为的三段论。 先说背景。大模型在运作上可用粗略分为训练和推理两大部分,在去年9月之前,训练的质量一直被视为重中之重,也就是通过所谓的算力堆叠,搭建万卡集群甚至十万卡集群来让大模型充分学习人类语料,#Kimi#DeepSeek#新模型
九原客2025-01-16 16:52:56Minimax的模型我原本以为只是一个就很随大流的模型。但实际测试发现在长文本输出层面有点惊艳。 具体可以下载海螺AI,随便找一篇长的英文论文,让他逐字翻译并输出为Markdown格式。Kimi 会拒绝翻译长论文,但是Minimax的模型可以持续输出很久(实测输出1w tokens还不停)同时还可以输出论文插图。#Minimax模型#长文本输出#海螺AI