勃勃OC2025-02-21 09:21:06这是在反串吗? Perplexity 为 R1 抹去言论审核,补充一些全球公认的事实信息,叫“在开源社区拉屎,对中国有敌意”? 中国大语言模型的训练数据集处理流程有几十万个关键词、人工黑名单、工信部备案30年 您是知道的吧 换言之,为什么要专门去除对中国不利的消息呢? 😳😳😳 #信息审查#中国#人工审核#人工智能#语言模型#数据处理#全球信息#开源社区#言论自由#中国政策
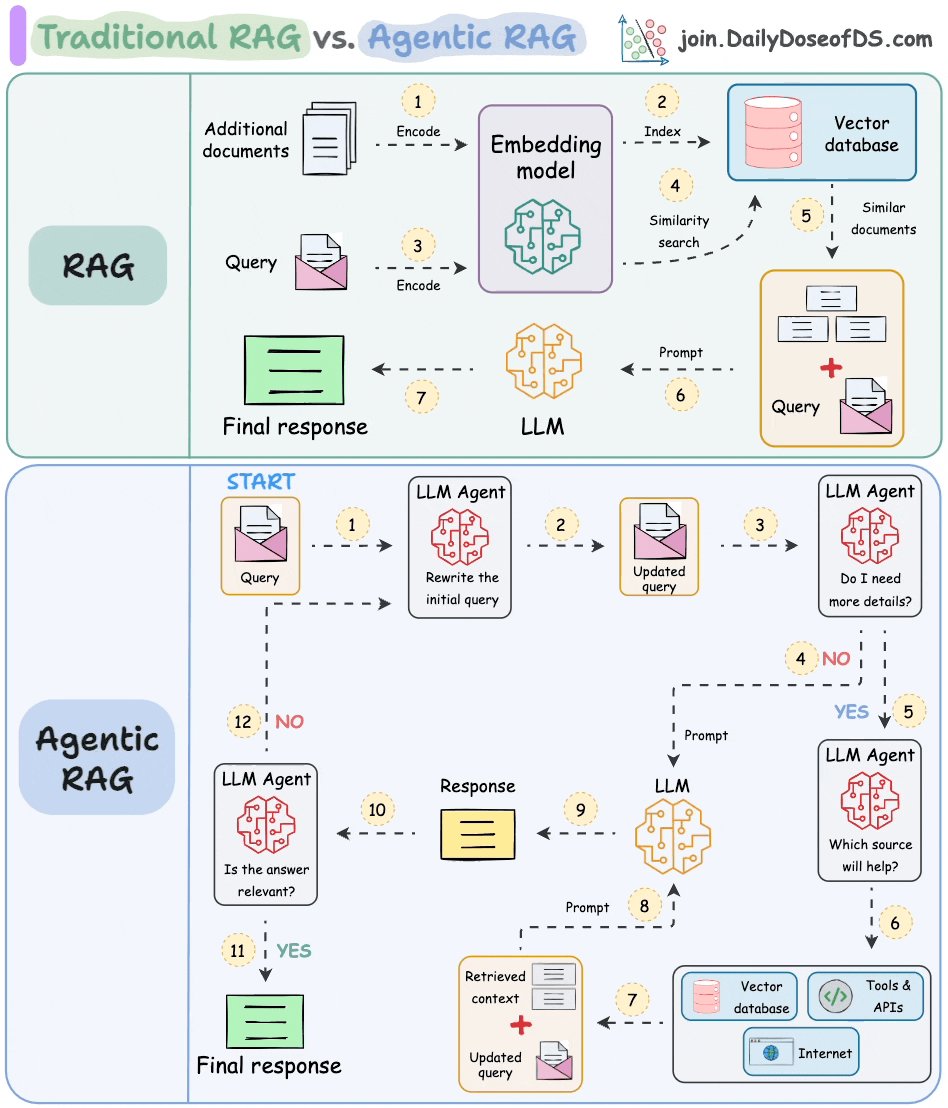
宝玉2025-01-19 04:06:36 DailyDoseofDS 这个图把传统 RAG 和 Agentic RAG 之间的差异分的比较清楚。 传统 RAG 就是先把文档向量化保存到向量数据库,然后在用户查询时,对用户的问题也做向量化,从向量数据库中找到相关的文档,再把问题和找出来的结果交给 LLM 去总结生成。 这种方式的优点就是简单,由于不需要太多次和 LLM 之间的交互,成本也相对低,但缺点是经常会因为做相似检索时,找不到合#RAG#Agentic RAG#向量数据库#LLM#自然语言处理#信息检索#数据处理
🇺🇸为自由而战-天山剑客🇺🇸2024-12-30 09:20:57🔥马斯克:特斯拉自动驾驶在黑暗中也能看的很清楚。 我们去掉了摄像头的后期处理,只保留数据。 计算机获取的数据远超摄像头呈现的画面。能捕捉极低光条件下光子差异,比你想象的还精确! 此外,这还让我们减少了13毫秒的延迟。 #马斯克#特斯拉#自动驾驶#黑暗视觉#摄像头技术#数据处理#延迟优化